概览
当您在 Agno 中运行一个团队时,您收到的响应(TeamRunResponse)会包含有关此次运行的详细指标。这些指标可帮助您了解跨团队领导者和团队成员的资源使用情况(例如 token 使用量和时间)、性能以及模型和工具调用的其他方面。
指标可在多个级别上获取:
- 每个消息:每个消息(助手、工具等)都有自己的指标。
- 每次工具调用:每次工具执行都有自己的指标。
- 每个成员运行:每个团队成员的运行都有自己的指标。
- 团队级别:
TeamRunResponse会聚合团队领导者消息的指标。 - 会话级别:跨会话中所有运行的聚合指标,包括团队领导者和所有团队成员。
指标的存储位置
TeamRunResponse.metrics: 团队领导者运行的聚合指标,以字典形式存储。TeamRunResponse.member_responses: 包含各自指标的各个成员响应。ToolExecution.metrics: 每个工具调用的指标。Message.metrics: 每个消息(助手、工具等)的指标。Team.session_metrics: 团队领导者会话级别的指标。Team.full_team_session_metrics: 会话级别的指标,包括所有团队成员的指标。
示例用法
假设您有一个执行某些任务的团队,并且您想在运行后分析指标。以下是访问和打印指标的方法:团队领导者指标
团队领导者消息指标
本节提供团队领导者每次消息响应的指标。所有“助手”响应都将具有此类指标,帮助您了解消息级别的性能和资源使用情况。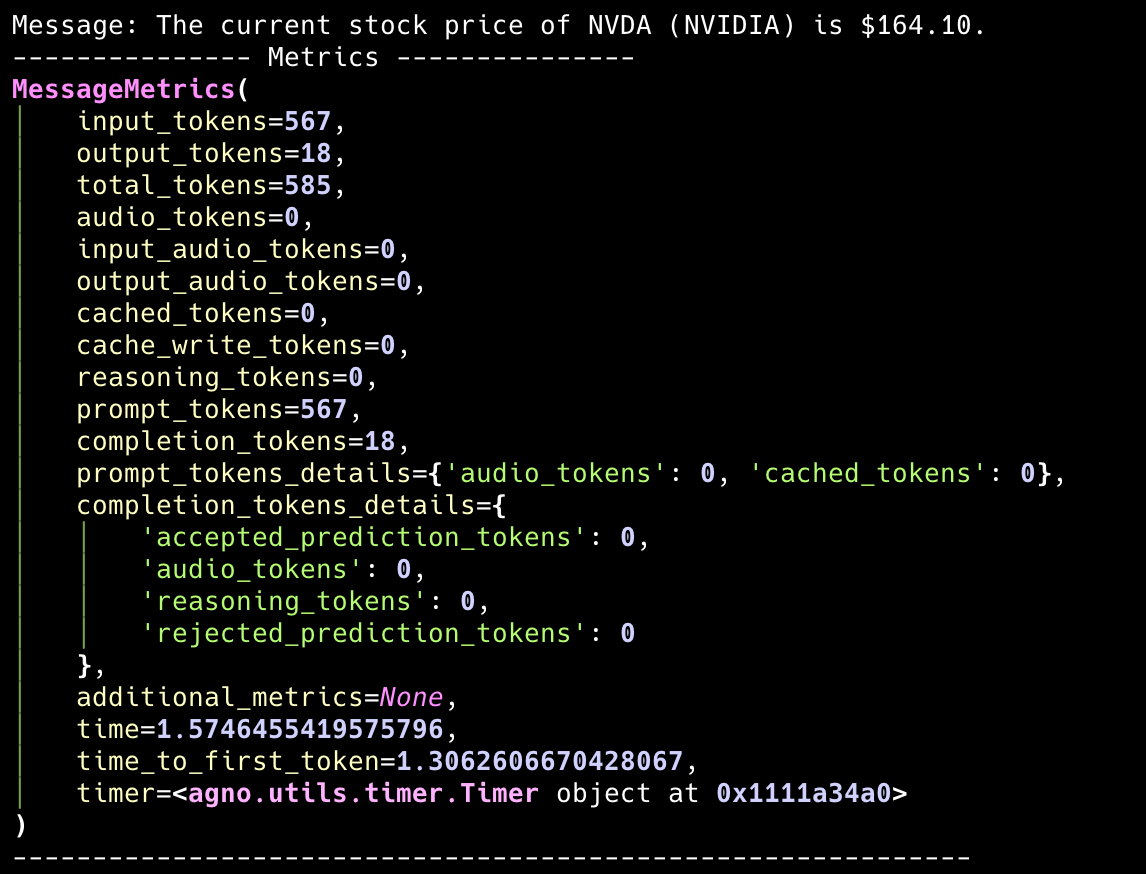
聚合团队领导者指标
聚合指标提供了团队领导者运行的全面视图。这包括所有消息和工具调用的摘要,让您对团队领导者的性能和资源使用情况有一个总体印象。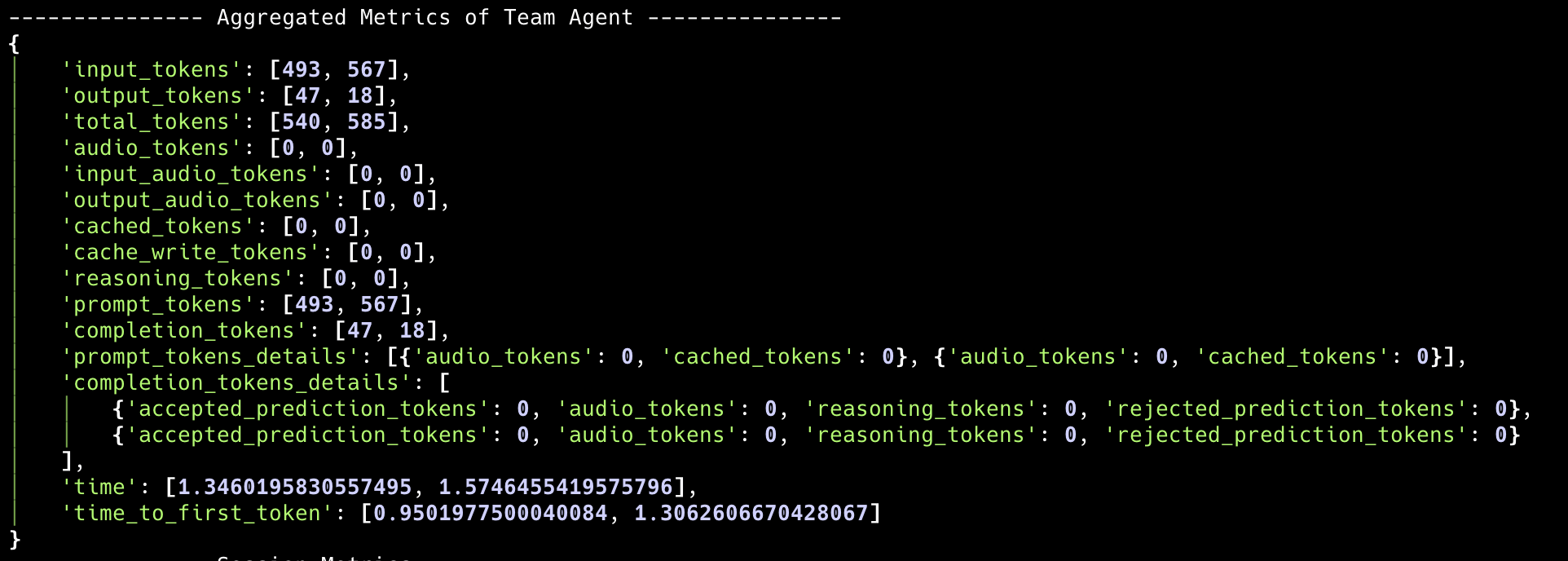
团队成员指标
单个成员指标
每个团队成员都有自己的指标,可以从team.run_response.member_responses 访问。这使您可以分析各个团队成员的性能。
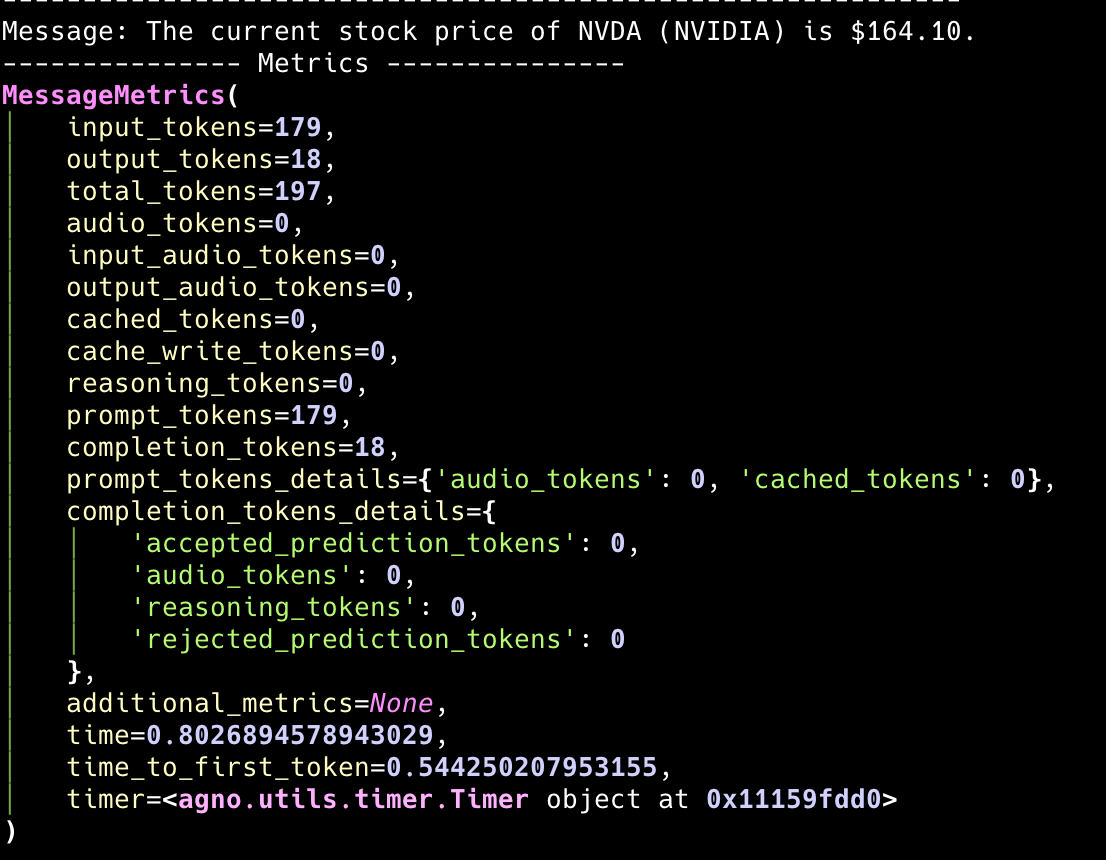
成员响应结构
每个成员响应包含:messages: 包含单个指标的消息列表metrics: 该成员运行的聚合指标tools: 各自包含指标的工具执行
会话级别指标
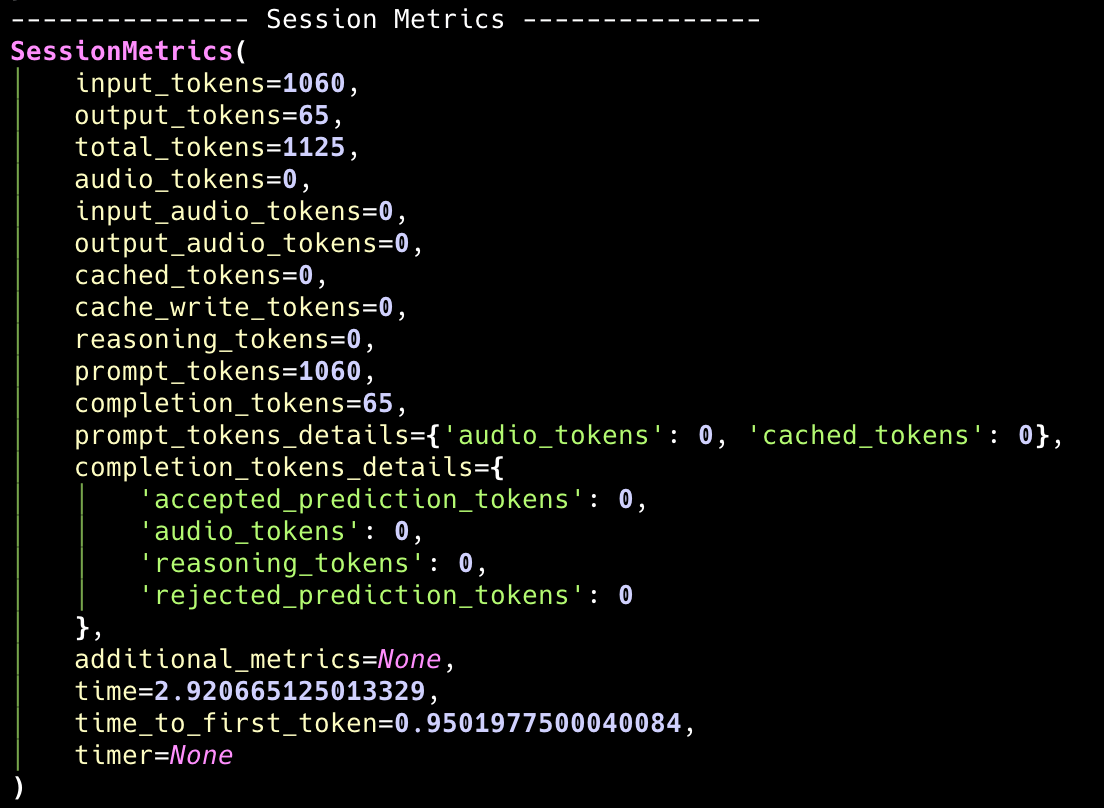
团队领导者会话指标
team.session_metrics 提供团队领导者在会话中所有运行的聚合指标。
完整团队会话指标
team.full_team_session_metrics 提供全面的指标,包括会话中所有运行的团队领导者和所有团队成员的指标。
指标如何聚合
团队领导者级别
- 每个消息:每个消息(助手、工具等)都有自己的指标对象。
- 运行级别:
TeamRunResponse.metrics是一个字典,其中每个键(例如 input_tokens)映射到运行中所有助手消息值的列表。 - 会话级别:
team.session_metrics聚合会话中所有团队领导者运行的指标。
团队成员级别
- 每个成员:每个团队成员都有自己单独跟踪的指标。
- 成员聚合:单个成员的指标在其各自的
RunResponse对象中进行聚合。 - 完整团队聚合:
team.full_team_session_metrics结合了团队领导者和所有团队成员的指标。
跨成员聚合
- 会话级别:
team.full_team_session_metrics提供了整个团队所有 token 使用量和性能指标的完整视图。
以编程方式访问成员指标
您可以通过多种方式访问单个成员指标:指标比较
MessageMetrics 参数
注意:并非所有字段都始终存在;具体取决于模型/工具和运行情况。
SessionMetrics 参数
注意:并非所有字段都始终存在;这取决于模型/工具和运行。