评估 (Evals) 是 Agent 和 Team 的单元测试,请明智地使用它们来衡量和改进它们的性能。Agno 提供了 3 个评估 Agent 的维度:
- 准确性 (Accuracy): Agent 的响应在多大程度上是完整/正确/精确的(LLM-as-a-judge)
- 性能 (Performance): Agent 的响应速度有多快,以及内存占用是多少?
- 可靠性 (Reliability): Agent 是否进行了预期的工具调用?
准确性
准确性评估使用输入/输出对来衡量您的 Agent 和 Team 相对于黄金标准答案的性能。使用一个更大的模型来评估 Agent 的响应(LLM-as-a-judge)。
在此示例中,AccuracyEval 将使用输入运行 Agent,然后使用一个更大的模型(o4-mini)根据提供的指南来评估 Agent 的响应。
from typing import Optional
from agno.agent import Agent
from agno.eval.accuracy import AccuracyEval, AccuracyResult
from agno.models.openai import OpenAIChat
from agno.tools.calculator import CalculatorTools
evaluation = AccuracyEval(
model=OpenAIChat(id="o4-mini"),
agent=Agent(model=OpenAIChat(id="gpt-4o"), tools=[CalculatorTools(enable_all=True)]),
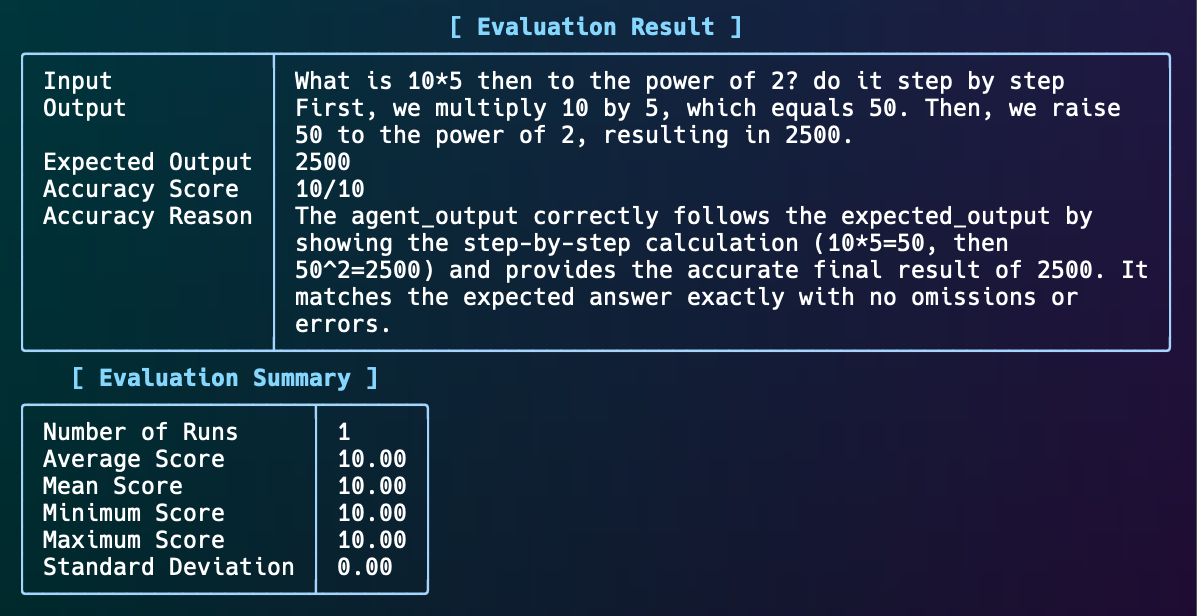
input="What is 10*5 then to the power of 2? do it step by step",
expected_output="2500",
additional_guidelines="Agent output should include the steps and the final answer.",
)
result: Optional[AccuracyResult] = evaluation.run(print_results=True)
assert result is not None and result.avg_score >= 8
AccuracyEval(无需运行 Agent)。
accuracy_eval_with_output.py
from typing import Optional
from agno.agent import Agent
from agno.eval.accuracy import AccuracyEval, AccuracyResult
from agno.models.openai import OpenAIChat
from agno.tools.calculator import CalculatorTools
evaluation = AccuracyEval(
model=OpenAIChat(id="o4-mini"),
input="What is 10*5 then to the power of 2? do it step by step",
expected_output="2500",
num_iterations=1,
)
result_with_given_answer: Optional[AccuracyResult] = evaluation.run_with_output(
output="2500", print_results=True
)
assert result_with_given_answer is not None and result_with_given_answer.avg_score >= 8
虽然延迟主要受模型 API 响应时间的影响,但我们仍应关注性能,并跟踪 Agent 或 Team 在有或没有某些组件时的性能。例如:了解在有或没有存储、内存,使用新提示或新模型时的平均延迟会很有用。
"""Run `pip install openai agno` to install dependencies."""
from agno.agent import Agent
from agno.models.openai import OpenAIChat
from agno.eval.perf import PerfEval
def simple_response():
agent = Agent(model=OpenAIChat(id='gpt-4o-mini'), system_message='Be concise, reply with one sentence.', add_history_to_messages=True)
response_1 = agent.run('What is the capital of France?')
print(response_1.content)
response_2 = agent.run('How many people live there?')
print(response_2.content)
return response_2.content
simple_response_perf = PerfEval(func=simple_response, num_iterations=1, warmup_runs=0)
if __name__ == "__main__":
simple_response_perf.run(print_results=True)
可靠性
是什么让 Agent 或 Team 变得可靠?
- 它是否进行了预期的工具调用?
- 它是否能优雅地处理错误?
- 它是否遵守模型 API 的速率限制?
第一个检查是确保 Agent 进行了预期的工具调用。这是一个示例:
from typing import Optional
from agno.agent import Agent
from agno.eval.reliability import ReliabilityEval, ReliabilityResult
from agno.tools.calculator import CalculatorTools
from agno.models.openai import OpenAIChat
from agno.run.response import RunResponse
def multiply_and_exponentiate():
agent=Agent(
model=OpenAIChat(id="gpt-4o-mini"),
tools=[CalculatorTools(add=True, multiply=True, exponentiate=True)],
)
response: RunResponse = agent.run("What is 10*5 then to the power of 2? do it step by step")
evaluation = ReliabilityEval(
agent_response=response,
expected_tool_calls=["multiply", "exponentiate"],
)
result: Optional[ReliabilityResult] = evaluation.run(print_results=True)
result.assert_passed()
if __name__ == "__main__":
multiply_and_exponentiate()